Seagate Technology is a United States-based data storage company with worldwide manufacturing facilities that generate huge amounts of manufacturing and testing data.
With petabytes of data accumulated over 20 years and more being generated each day, it was imperative for Seagate to have systems in place to ensure the cost of collecting, storing, and processing data did not exceed their return on investment (ROI).
Seagate’s on-premises big data stack was built on Oracle Data Warehouse for low latency query access and Hortonworks Hadoop Distribution with Apache Hive and Apache Tez for big data storage and query processing.
That stack was too costly and time-consuming for the large amounts of data being processed (approximately 2 petabytes) and many users queried it.
In addition, end users were dissatisfied because the queries were taking too long to complete and sometimes failed. Systems maintenance and upgrades were compounding the problem.
Seagate asked Mactores Cognition, an AWS Partner Network (APN) Advanced Consulting Partner, to evaluate and deliver an alternative data platform to process petabytes of data with consistent performance. It needed to lower query processing time and total cost of ownership (TCO), and provide the scalability required to support about 2,000 daily users.
In this post, we will describe the three migration options Mactores tested, the results each one produced, and the selected architecture of the solution Seagate.
About Amazon EMR Technologies
This summarizes the Amazon EMR technologies Mactores explored for its Seagate solution.
Mactores is an Amazon EMR Delivery Partner. The AWS Service Delivery Program endorses top APN Consulting Partners that deeply understand specific AWS services, such as Amazon EMR.
Learn more about using Mactores to migrate to Amazon EMR.
Amazon EMR
Amazon EMR is a highly scalable big data platform that supports open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi (Incubating), and Presto.
When you combine it with the dynamic scalability of Amazon Elastic Compute Cloud (Amazon EC2) and scalable storage of Amazon Simple Storage Service (Amazon S3), you get the elasticity to run the petabyte-scale analysis for a fraction of the cost of traditional on-premises clusters.
IDC studied nine companies that leveraged Amazon EMR to run big data frameworks at scale and found that, on average, they lowered the total cost of ownership by 57 percent and experienced a 99 percent reduction in unplanned downtime. Learn more from IDC about the business impact of Amazon EMR, including an average 342 percent five-year ROI.
You can run Amazon EMR use cases on single-purpose, short-lived clusters that automatically scale to meet demand or on long-running, highly-available clusters using the new multi master deployment mode.
Presto
Presto (or PrestoDB) is an open-source, distributed SQL query engine designed from the ground up for fast analytic queries against data of any size. It supports both non-relational sources, such as the Hadoop Distributed File System (HDFS), Amazon S3, and HBase, and relational data sources such as MySQL, PostgreSQL and Amazon Redshift.
Presto can query data where it’s stored, without needing to move data into a separate analytics system. Query execution runs in parallel over a pure memory-based architecture, with most results returning in seconds.
Presto on Amazon EMR
You can launch a Presto on Amazon EMR cluster in minutes. You don’t need to worry about node provisioning, cluster setup, configuration, or cluster tuning. Amazon EMR takes care of these tasks so you can focus on analysis.
You can quickly and easily create managed Presto clusters from the AWS Management Console, AWS Command Line Interface (CLI), or the Amazon EMR API. You can choose from a wide variety of Amazon EC2 instances, and use AWS Auto Scaling to dynamically add and remove capacity, or launch long-running or ephemeral clusters to match your workload. You can also add other Hadoop ecosystem applications onto your cluster.
Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse service that analyzes data using your existing business intelligence tools. It’s optimized for datasets ranging from a few hundred gigabytes to a petabyte or more, and is 50 percent less expensive than other cloud data warehouses.
Migration Options We Tested
We deployed Mactores’s own comprehensive big data assessment process called HEXA Audit, which performed an in-depth analysis of Seagate’s big data requirements based on the following factors:
-
End user tools: We needed to know what tools Seagate end users were currently using to query the data.
-
Analysis of long-running queries: We needed to know what queries were being used by the user, and if those queries were using any custom functions that may require custom solutions for migration.
-
Security and access control: We had to collaborate with Seagate’s information security team to understand their access control policies.
-
Storage: It was important to understand the size of the data, storage technology, and feasibility of the migration to the new storage solution.
To reduce the time and cost of the query execution, we recommended transforming Seagate’s current data platform to Amazon EMR.
This included the following three options:
-
Migrate Seagate’s on-premises big data stack to Amazon EMR with S3 as storage, and Apache Spark, Apache Map Reduce, and Apache Tez as query engines.
-
Migrate to Amazon EMR with S3 as storage and Presto on Amazon EMR as the query engine.
-
Migrate to Amazon Redshift as data warehouse and Amazon Redshift Spectrum for processing from S3 as a big data storage.
Mactores performed a quick proof of concept (PoC) with Seagate data to benchmark all three options. Following are the results we obtained.
Amazon EMR with Apache Tools
Migrating to Amazon EMR with Amazon S3 for storage allowed Seagate to keep its compute and storage resources separate, reducing their TCO significantly. Queries that used to execute in 7-8 hours on Seagate’s legacy platform now took less than 20 minutes.
Here are some details of the migration:
-
Apache Map Reduce was the slowest query execution engine due to the high disk IO required to process customers' queries.
-
Apache Tez was significantly faster than Apache Map Reduce while keeping disk IO the same.
-
Apache Spark was slightly faster than Apache Tez with no IO blocking and was best suited for the solution.
While Spark was fast enough to increase the query processing, it could not match the query execution time Seagate was expecting. On the other hand, Spark could execute very large queries/jobs that required 10TB and above of memory.
Amazon EMR with Presto
Migrating to Amazon EMR offered separation of computing and storage, but Presto offered additional scalability with Amazon EMR. Presto was the fastest among all query engines we evaluated for Seagate queries.
For 70-75 percent of the queries, Presto outperformed Oracle Data Warehouse query execution while supporting massive amounts of data stored on Amazon S3. However, Seagate faced challenges with Presto for questions consuming more than 10TB of memory. Besides that, there was no retry mechanism like Apache Spark in Presto to manage node restarts or loss of spot instances.
Amazon Redshift with Spectrum
Amazon Redshift offered a fast query performance with consistency across multiple executions of the same query. While the performance of Amazon Redshift and Presto were similar, the cost of using terabytes of Amazon Redshift cluster and Amazon Redshift Spectrum for S3 data was significantly higher.
Part of the reason Amazon Redshift and Amazon Redshift Spectrum had higher TCO is that Presto on Amazon EMR supports spot instances, which directly affected the total cost of running the data platform.
Results
The benchmarking consisted of a workload that progressively increased incoming load for some time, followed by an idle period. We ran five queries: joins, group by, and sort. These queries ran on table sizes between 10GB and 10TB, containing millions to billions of rows.
With the default configurations and comparable infrastructure, we observed that when running one query at a time Presto on Amazon EMR would finish the queries much faster than Apache Spark and Amazon Redshift.
For the load test, when five queries ran concurrently with a batch interval of 60 seconds, Presto still performed better than Apache Spark and Amazon Redshift.
| Query | Presto (minutes) | Spark (Minutes) | Redshift (Minutes) |
| Q1 | 4:00 | 29:17 | 7:29 |
| Q2 | 5:40 | 38:25 | 35:31 |
| Q3 | 24:30 | 24:41 | 14:10 |
| Q4 | 15:35 | 18:15 | 19:12 |
| Q5 | 61:15 | 19:40 | 33:54 |
Here are the same results of the load test in a different design format.
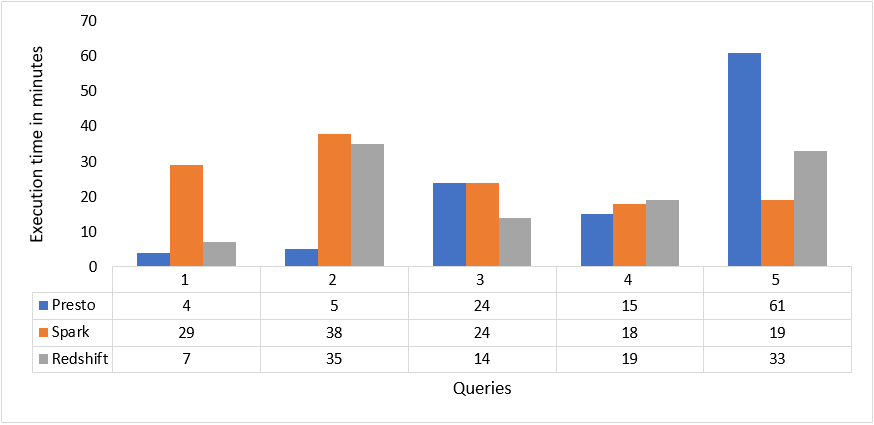
Figure 1 – Results of the load test (graphic form).
The chart in Figure 2 shows the output of some of the queries included in the testing of Apache Map Reduce vs. Apache Spark vs. Presto.
As observed, the execution time for Presto was significantly less than Apache Map Reduce and Apache Spark.
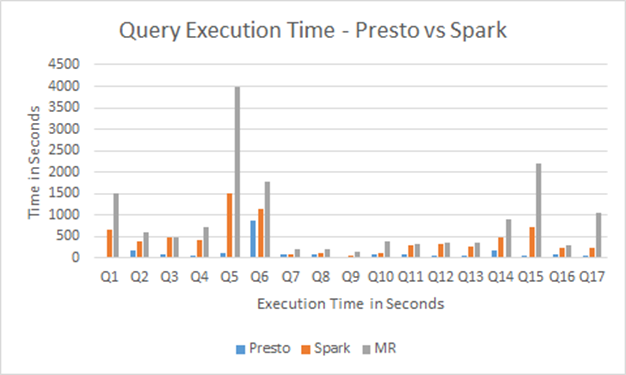
Figure 2 – Comparison of query execution time.
Our Recommendations
Presto on Amazon EMR consistently outperformed Apache Spark and Amazon Redshift in query execution time. As a result of our PoC, we recommended that Seagate adopt Presto on Amazon EMR for querying massive amounts of data.
After working closely with our team to fully understand the potential solutions, Seagate moved forward with two query engines: Hive on Spark and Presto on Amazon EMR.
To meet the query and scale performance requirements, Seagate would use Presto on Amazon EMR for queries less than 10TB of memory and use Hive on Spark for larger queries with transient Amazon EMR clusters leveraging Amazon EC2 Spot Instances.
Configuration Parameters for Presto
When a Presto cluster runs queries containing hundreds of billions of rows concurrently, it can hit an upper limit for some of the parameters. To avoid this problem, you have to understand how to configure these parameters in the
config.properties and jvm.properties files:-
Presto memory
-
Query optimization
-
Query fault tolerance
-
OS-level parameters
-
Presto security
Presto Memory Parameters
These parameters configure the amount of memory consumed by Presto on AWS:
-
query.max-memory: This parameter, contained in the
presto.configproperties file, is a cluster-level memory limit. It specifies the maximum memory a query can take, aggregated across all nodes. Setting a higher value of query.max-memory avoids a query hitting an upper limit of memory. - query.max-memory-per-node: This parameter determines the maximum memory a query can use on one node. Ideally, the value of this parameter should be equal to 40 percent of worker instance memory.
- Java Virtual Machine (JVM) memory: The
jvm.propertiesfile contains details related to the JVM. Since the memory of the system is being shared between the system, Java, and Presto configuration, it’s important you allocate the right memory to the JVM and spare enough for the OS. The JVM memory should ideally be 80 percent of the total memory of the instance. - Presto Spill to Disk: Presto, by default, is an in-memory query engine, which stores intermediate operation results only in memory. However, this does not work well with memory-intensive queries. The mechanism is like OS-level page swapping. Therefore, it’s important to enable the Spill to Disk for Presto to use disk memory to store the temporary data.
- Presto Memory Architecture: Presto divides memory in each node across two pools: general and reserved. Each memory pool has a certain role to play in the execution of the query. The reserved pool is used only when a worker node exhausts all its memory in the general pool.
The reserved pool fast tracks one particular query and guarantees its completion. However, due to this behavior, the execution of all other queries suffers since the other queries on that particular node are stalled until that one query completes.
Query Optimization Parameters
These parameters configure the behavior of queries:
- Cost-Based Optimization (CBO): The CBO makes decisions based on several factors, including shape of the query, filters, and table statistics. Enable the CBO parameter in Presto to optimize the query structure before running.
- Session properties: Session properties provide the flexibility to control the behavior for queries based on their properties. Session properties control resource usage, enable or disable features, and change query characteristics. When running heavy queries, one of the important session properties that will help is
query_max_execution_time. - Queueing mechanism: Queries being submitted to the Presto cluster can be pushed to different queues based on the content of the query or the client tags of the query. Each queue can then be configured to different parameters to control resource usage or use different features.
Related Parameters
These parameters configure fault tolerance, number of open files, and LDAP authentication:
-
Presto retry mechanism: When a node fails, by default Presto will terminate the queries that were using that particular node for querying data. This makes it difficult to scale up and down Presto with AWS Auto Scaling features. Configure the Presto retry mechanism to avoid this problem. One trade-off Presto makes to achieve lower latency for SQL queries is to not care about mid-query fault tolerance. If any of the Presto worker nodes experience a failure, such as getting terminated, queries in progress will abort and need a restart. Due to the absence of the retry mechanism, it’s difficult to achieve auto-scaling of the cluster, as auto-scaling in Amazon EMR (when scaling down) terminates random instances based on the aggregate memory of the cluster.
-
Ulimits: The number of open files and running processes in a Linux system is limited by default. We need to increase this limit in the
ulimits.confof the operating system. -
Presto LDAP: LDAP Authentication on Presto requires HTTPS to be enabled and a keystore to be created. The keystore then needs to be passed on to the client to be added to the property.
Solution Architecture
To set up the new stack on AWS, we migrated the data to the storage location on Amazon S3. To set up Amazon EMR, we considered the networking configuration, security group policies, and authentication per Seagate security compliance needs.
We adjusted some Hadoop and Hive parameters to obtain optimum utilization of the Amazon EMR cluster and S3. The following architecture shows Seagate’s setup after migration.
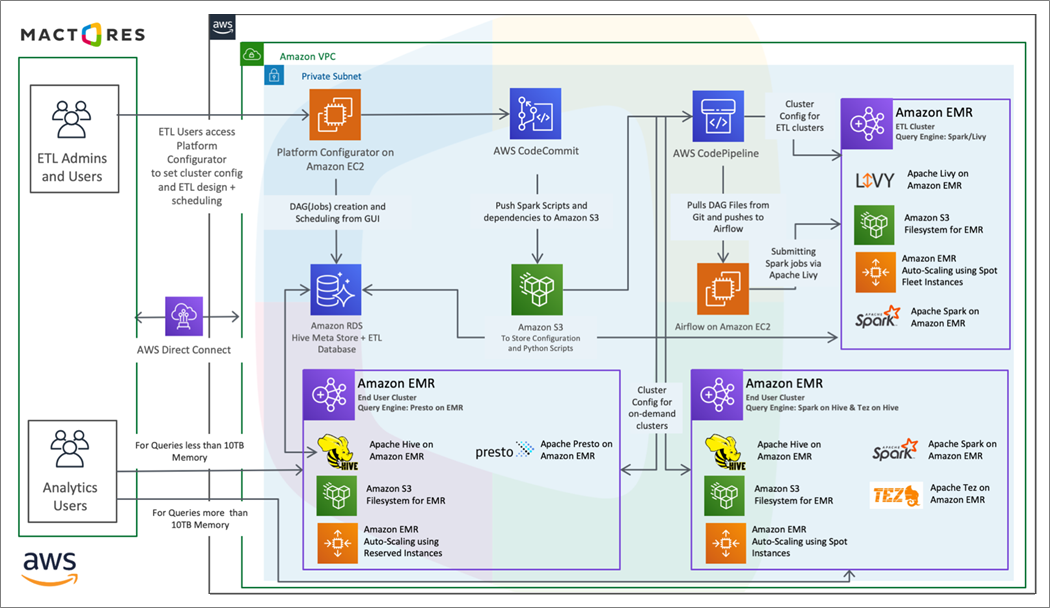
Figure 3 – Spark/Presto on AWS.
Conclusion
The migration to Amazon EMR Presto SQL allowed Seagate Technologies to continue processing petabytes of data fast, at a reduced cost of Amazon EMR, and resulted in a 10x improvement of the execution time of queries.
Since we deployed the solution with network load balancing, Seagate could switch clusters without impacting their end user. Seagate saved a lot of CPU time, and their end users could get query results in minutes rather than hours. This improved the overall efficiency of both their Amazon EMR cluster and business operations. Let's talk.

